
AFFILIAZIONE
università degli studi di trieste
AUTORE PRINCIPALE
Ajcevic Milos
VALUTA IL CHALLENGE
GRUPPO DI LAVORO
Ajcevic Milos – università degli studi di trieste, trieste
Iscra Katerina – università degli studi di trieste, trieste
Miladinovic Aleksandar – università degli studi di trieste, trieste
Starita Serena – università degli studi di trieste, trieste
Prof. Accardo Agostino – università degli studi di trieste, trieste
AREA TEMATICA
Applicazioni innovative di bioingegneria
ABSTRACT
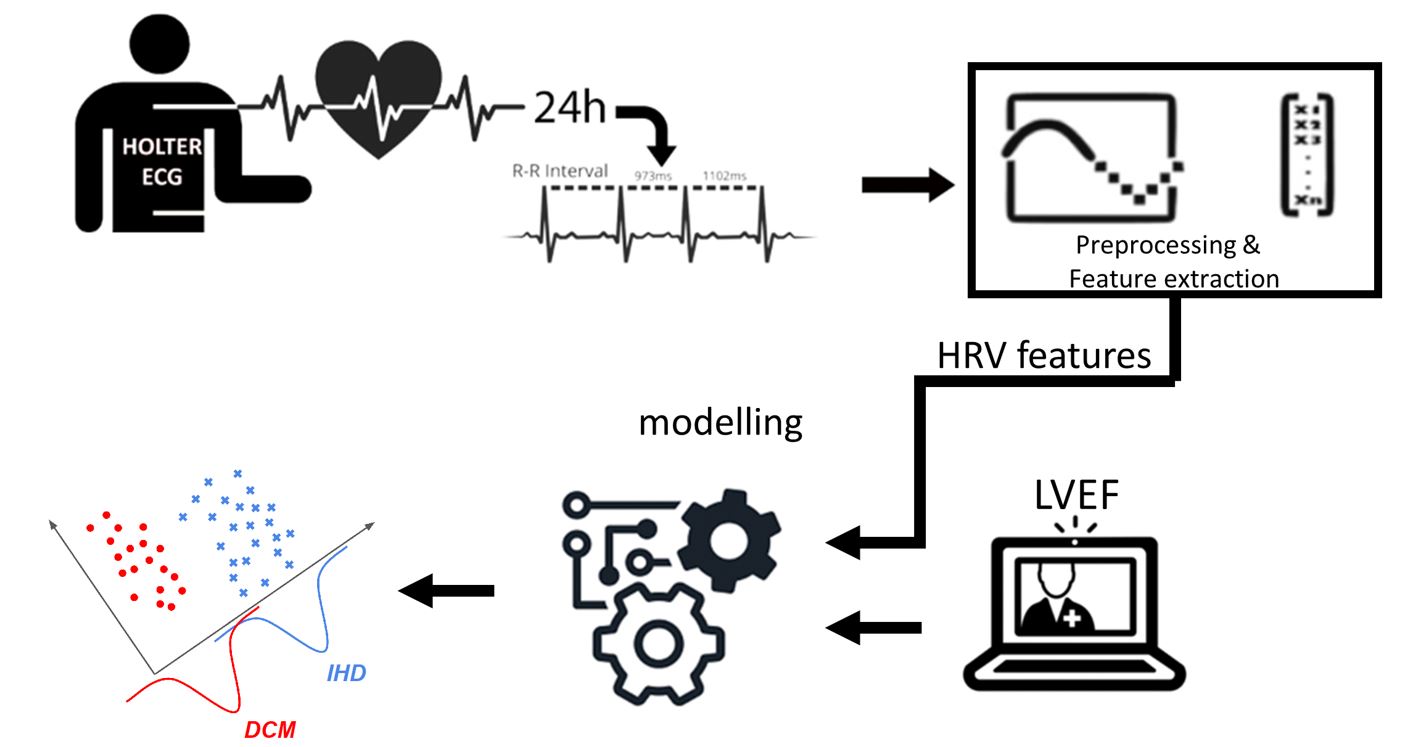
La diagnosi differenziale tra cardiopatia ischemica (IHD) e la cardiomiopatia dilatativa (DCM), in particolar modo nelle prime fasi della malattia, può spesso risultare complessa richiedendo tecniche invasive. La frazione di eiezione del ventricolo sinistro (LVEF) e l’analisi della variabilità cardiaca (HRV) si sono dimostrate due tecniche non-invasive molto utili nella diagnosi di diverse malattie cardiache. Negli ultimi anni l’interesse nell’applicare le tecniche di machine learning per aiutare i clinici nella diagnosi differenziale è cresciuto notevolmente. D’altra parte, la maggioranza dei modelli prodotti sono black-box, difficilmente interpretabili dagli esperti clinici.
L’obiettivo del progetto era quello di studiare e sviluppare le prestazioni dei modelli interpretabili e clinicamente plausibili applicati per la diagnosi differenziale nelle prime fasi di DCM e IHD basati sui parametri HRV e il valore della LVEF.
Lo studio comprendeva 313 soggetti: 196 IHD e 117 DCM. I modelli sono stati prodotti mediante tre tecniche di machine learning (l’albero decisionale, la regressione logistica e naive Bayes) considerando il dataset delle features HRV e LVEF selezionate con il metodo information gain.
I risultati hanno mostrato che i parametri che portano più informazione nella classificazione tra IHD e DCM erano LVEF, LF, NN50, pNN50 e meanRR. Il modello naive Bayes con un’accuratezza di classificazione del 73,5% è risultato essere migliore rispetto ai modelli ottenuti dall’albero decisionale e dalla regressione logistica con un’accuratezza rispettivamente del 67,4% e del 67,1%. Inoltre, abbiamo dimostrato che i modelli prodotti insieme ai nomogrammi consentono un’interpretazione probabilistica dell’output della classificazione tra IHD e DCM. L’interpretabilità del modello attraverso il nomogramma risulta dunque essere un fattore importante, che consente ai clinici di seguire il processo decisionale del modello e in seguito di supportare la diagnosi differenziale di nuovi soggetti.


